3. ПОДГОТОВКА К СОЗДАНИЮ ПРОЕКТА
Рассмотрим создание проекта на примере игры The Legend of Zelda: Links Awakening DX (GBC).
Здесь показан только один из множества возможных путей решения задачи по нахождению всех нужных циферок для создания проекта. Шрифты можно увидеть при помощи понравившегося тайлового редактора, а тексты при помощи понравившегося HEX- редактора. Они тут не запакованы, и объёмы ROM-а не столь велики, чтобы чего-то не найти. Как видим, текст читается и имеет кодировку, похожую на ASCII.











Рисунок 2. Предварительное исследование. Поиск шрифтов и текстов в CrystalTile 2
О том, как находить указатели на эту платформу (Game Boy / Game Boy Color), можно прочитать здесь:
chief-net ru/index.php?option=com_content&task=view&id=109&Itemid=33
Мне удобнее разбирать ROM на блоки (либо файлы), выбрать те, где есть текст и указатели и работать уже конкретно с ними. Здесь, в связи с особенностями архитектуры консоли, будут блоки по 16 килобайт, они получены при помощи простой и понятной программки Cracker’а и небольшого батника:
zelda64rus ucoz ru/_fr/5/Cut_und_analyze.7z
Теперь можно записать куда-нибудь адреса начала и окончания текстов (нули, идущие после текста, в данном случае можно считать текстом).
Мне удобно делать это при помощи Hex-редактора (здесь Hex Workshop) и электронных таблиц (здесь Excel).


Рисунок 3. Копируем адреса начала текстов из каждого блока
В блоке 28_00070000.bin, начиная c адреса 0x0001 и заканчивая 0x0560, содержатся указатели. Копируем их в отдельный файл и удалим первый байт: 01.





Рисунок 4. Копируем указатели
Приведём к удобному виду и скопируем указатели в текстовый редактор (здесь AkelPad). Удалим лишние пробелы и увидим, сколько же у нас всего указателей и предположительное количество строк.



Рисунок 5. Удаляем лишнее
Выделяем всё и опять копируем. В Excel выделяем столбец, выбираем текстовый формат ячеек и вставляем сюда полученные указатели. Далее можно их перевернуть (LE -> BE) и сравнить с адресами начала текстов (+ 0x4000).
Теперь и указатели можно разбить на 5 групп, т.к. для титров тут указателей не нашлось. Получим начальный и конечный адреса для каждой группы указателей. Всё это, конечно, можно найти и посчитать при помощи Hex-редактора и калькулятора, но мне лень.
Нам он не нужен, т.к. указателем на текст явно не является, а для чего он был нужен разработчикам, меня не интересовало.
Таблицы для перекодировки текста тоже удобно хранить подобным образом. А лишние знаки табуляции удалять в текстовом редакторе, непосредственно перед сохранением в файл (*.tbl).
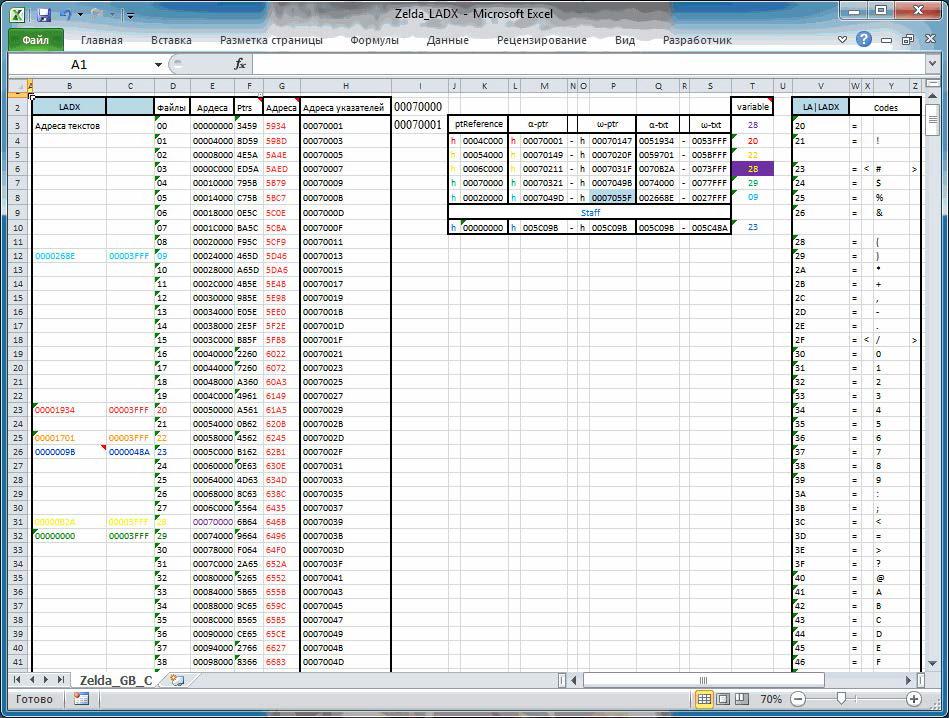
Рисунок 6. Все циферки, необходимые для создания проекта, в одном месте
Таблицу символов можно получить различными способами. В данном случае карта символов шрифта не была найдена. Чтобы составить полную таблицу символов, все тексты, кроме титров, копировались в один отдельный файл.

Рисунок 7. Тексты из всех блоков (кроме титров) скопированы в один файл
Когда весь диалоговый текст находится в одном файле, то можно определить все коды символов и специальные коды, которые в нём содержатся. Сразу же видим FF в конце текста, — предположим, что это символ конца строки и тут же это проверим (Рисунок 8).


Рисунок 8. Проверяем «FF»
Скопируем эти коды в текстовый редактор, а здесь заменим на 00, чтобы больше к ним не возвращаться.
Повторяем процедуру до нахождения всех нужных кодов. Коды букв известны, т.к. текст читается, а вот апостроф явно имеет код, отличный от стандартного.
других символов конца строки (здесь ещё можно обратить внимание на то, что адреса всех найденных FF можно скопировать в блокнот и опять же использовать для проверки, сравнив с указателями). Проверим теперь все возможные коды c F?. Пролистаем немножко и найдём ещё один код, похожий на конец строки: FE. И ещё коды F0, F1, F2 и F3, которые впоследствии окажутся стрелочками (Рисунок 9).


Рисунок 9. Проверяем «F?»




Рисунок 10. Заменяем все «F?», переходим к следующей группе кодов «E?» и т.д.
Коды оставшихся символов алфавита (европейские символы, среди ромхакеров иногда называемые «умляуты»), которые есть в шрифте, но в этом тексте не используются, можно узнать уже после составления проекта с помощью Kruptar и эмулятора.
Для того, чтобы читались все символы, в том числе японские, какие-либо значки или европейские «умляуты», всегда рекомендую сохранять таблицу в кодировке Unicode (здесь UTF-16 LE), коды, отличные от символов, заключать в скобки (тут [квадратные] ).
Если известно, что код обозначает — именовать, если нет — нумеровать (либо писать сам код, если он короткий).
После ends идут символы конца строки. Здесь таковых получилось два.
Теперь мы знаем абсолютные адреса текстов и указателей. Есть таблица с оригинальным алфавитом и служебными кодами (за ними бывают скрыты иконки, звуки, имена и прочие функции).
Можно возвращаться к созданию проекта в Kruptar.
Прикрепленные изображения